

Obecnie dostępne zasoby sieci neuronowych zdolnych do głębokiego uczenia nie nadążają za trendami ze względu na rosnącą złożoność, rozbieżne wymagania, oraz ograniczenia narzucane przez istniejące architektury sprzętowe. Kilku naukowców z firmy Nvidia opublikowało niedawno artykuł techniczny przedstawiający dążenie firmy do stworzenia modułów wielochipowych (MCM), aby sprostać tym zmieniającym się wymaganiom. Artykuł przedstawia stanowisko zespołu w sprawie korzyści płynących z zastosowania procesora graficznego typu Composable-On-Package (COPA), który lepiej radzi sobie z różnymi rodzajami obciążeń związanych z SI.
Nvidia COPA-GPU
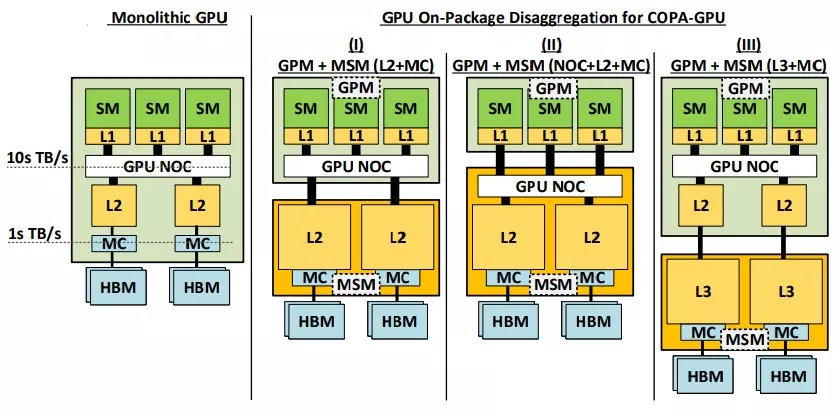
Procesory graficzne (GPU) stały się jednym z głównych zasobów wspierających SI dzięki swoim możliwościom wykonywania wielu obliczeń jednocześnie. To jednak nie zawsze wystarczy. COPA-GPU powstało w wyniku uświadomienia sobie, że tradycyjne projekty konwergentnych układów GPU wykorzystujące sprzęt specyficzny dla danej dziedziny szybko przestają być praktycznym rozwiązaniem. Te konwergentne rozwiązania GPU opierają się na architekturze składającej się z tradycyjnych układów, jak również z wyspecjalizowanego sprzętu, takiego jak pamięć o wysokiej przepustowości (HBM), rdzenie Tensor (Nvidia)/Matrix Cores (AMD), rdzenie ray tracing (RT), itp. Taka konwergentna konstrukcja skutkuje sprzętem, który może być dobrze przystosowany do niektórych zadań, ale nieefektywny przy wykonywaniu innych.
Zobacz też: Tak wyglądałby wszechświat, gdyby Ziemia miała 1,2 cm — niesamowita animacja
W przeciwieństwie do obecnych monolitycznych konstrukcji GPU, które łączą wszystkie specyficzne komponenty wykonawcze i buforowanie w jednym pakiecie, architektura COPA-GPU zapewnia możliwość mieszania i dopasowywania wielu bloków sprzętowych, aby lepiej dostosować się do dynamicznych obciążeń występujących we współczesnych środowiskach wysokowydajnych obliczeń (HPC) i głębokiego uczenia (DL). Ta możliwość wykorzystania większej liczby konfiguracji i dostosowania do wielu rodzajów obciążeń może zaowocować wyższym poziomem ponownego wykorzystania GPU i, co ważniejsze, większą zdolnością naukowców do przesuwania granic możliwości przy wykorzystaniu istniejących zasobów.
Źródło: TechSpot