
Każdy może stworzyć swój własny czat z AI, który nie wymaga dostępu do internetu i możemy działać z nim lokalnie na swoim komputerze. Jak przygotować własnego Chata GPT, opowiadałem dwa miesiące temu. Z kolei w maju przyjrzeliśmy się bliżej najnowszej odsłonie modelu od Mety, a więc Llama 3. Niemniej w ramach tego ostatniego materiału wspomniałem, że samych modeli językowych i ich różnorakich wariacji jest mnóstwo. W takim razie jak dobrać najlepszy pod swoje potrzeby? Najlepiej spojrzeć na rankingi, których jest równie dużo.
Spis treści
Rankingi najlepszych modeli LLM, czyli sztuka wyboru

Na co dzień staram się na przemian używać Chat GPT od OpenAI, które jest ewidentnym liderem, jeśli chodzi o jakość oferowanych usług, z mniej znanymi rozwiązaniami. Dlatego od czasu do czasu staram się też sprawdzać inne modele językowe pod konkretne potrzeby. Wykorzystuję w tym celu program LM Studio i bazę Hugging Face.
Klasycznie przypominam, że nie potrzebujemy do tego niesamowicie mocnego sprzętu i szeregu serwerów. W moim przypadku jest to laptop bez dedykowanej karty graficznej, ale z procesorem AMD Ryzen 7 7840U, czyli ze wsparciem dla Ryzen AI. Kluczowa w tym wszystkim jest też pamięć operacyjna GPU (VRAM), gdzie im więcej, tym po prostu lepiej.
Hugging Face – największa baza z największym rankingiem
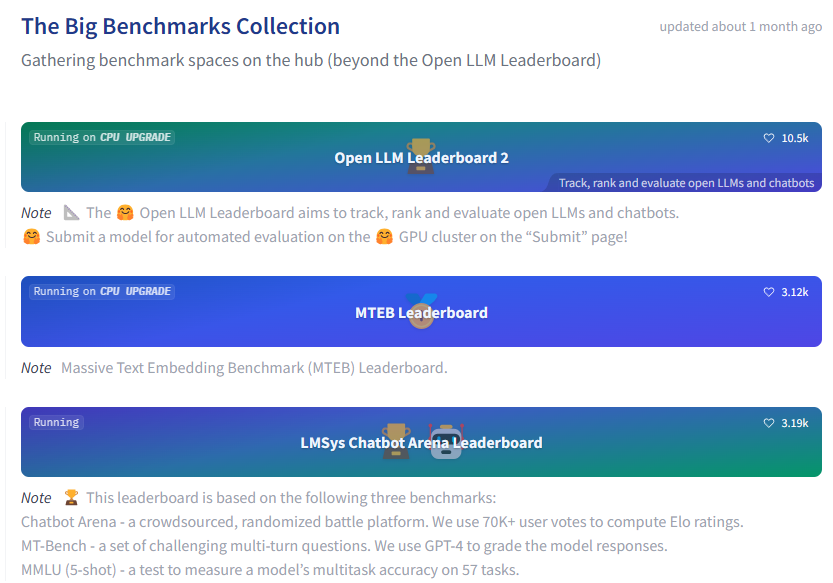
Hugging Face to nie tylko baza, ale też szereg rankingów, które pozwalają ocenić użyteczność i jakość konkretnych modeli językowych pod konkretne potrzeby. Musicie wiedzieć, że można podchodzić ogólnie do modeli LLM i wybrać najbardziej uniwersalny (patrz: ChatGPT od OpenAI).
Jednak, mając konkretne wymagania, np. weryfikacja kodu lub tłumaczenie tekstu, może się okazać, że nie ma sensu wydawać pieniędzy na platformę OpenAI, a wystarczy właśnie nasz sprzęt i darmowy model LLM. Dlatego obowiązkowo sprawdźcie najpopularniejsze benchmarki dostępne na Hugging Face.
To, co doceniam w Hugging Face, to znaczący nacisk na kategoryzowanie licencji, w ramach których możemy korzystać z konkretnych modeli językowych. Darmowe propozycje (Open Source) również mają wiele podkategorii, więc warto zwracać na to uwagę, np. w ramach Open LLM Leaderboard.
OpenRouter – kategoryzacja pełną gębą
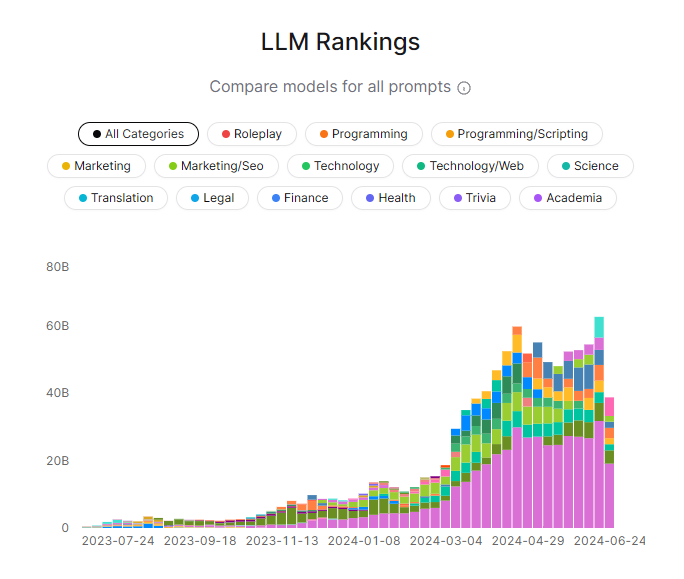
O ile Hugging Face może okazać się dla wielu osób zbyt skomplikowany na samym początku, tak OpenRouter mówi wprost, pod jakim względem ocenia konkretne model LLM w swoich rankingach. Mówimy w tym wypadku o znajomości świata finansów, tłumaczeniach, programowaniu i kilku innych.
Jednocześnie, co bardzo istotne w świecie AI, możemy weryfikować oceny w konkretnym oknie czasowym. Dlatego nie mamy zaburzanych wyników poprzez świetne rezultaty modeli sprzed wielu tygodni, kiedy w międzyczasie pojawiło się wiele nowych, lepszych.
Co to są tokeny, okno kontekstowe i inne?
W ramach różnorakich rankingów na pewno przewiną się wam pojęcia, które nie muszą być do końca zrozumiałe, jeśli dopiero zaczynacie swoją przygodę z LLM. Idąc po kolei, warto wiedzieć, że:
- Token to podstawowa jednostka modeli językowych, która może odnosić się do całych słów, ich części lub pojedynczych znaków;
- Token/s, czyli niejako wydajność generowania odpowiedzi – ile dany model jest w stanie w konkretnym czasie wygenerować tokenów na sekundę. Im wyższy wynik, tym lepiej;
- Context Window to maksymalna liczba tokenów, którą dany model jest w stanie przetworzyć w jednym zapytaniu. Im większy wynik, tym lepiej;
- Latency (First Chunk), czyli określenie opóźnienia potrzebnego na wygenerowanie pierwszej części odpowiedzi. Im mniejszy wynik, tym lepiej.
Z racji, że skupiamy się na darmowych modelach, tak pomijam aspekty finansowe. Niemniej przy wielu rankingach ważnym przelicznikiem jest to, ile kosztuje zarówno zrozumienie, jak i wygenerowanie konkretnej liczby tokenów. Jeśli jednak interesuje was ranking płatnych rozwiązań, to możecie spojrzeć na zestawienie Artifical Analysis.
Specjalny ranking dla Polaków
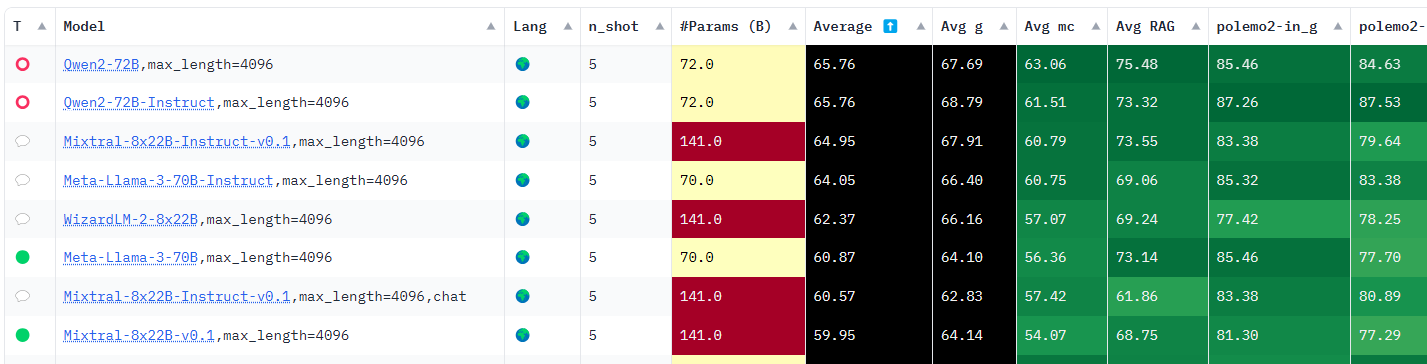
A dokładniej specjalny ranking stworzony z myślą o języku polskim. Autorzy tego zestawienia stworzyli swój własny benchmark, który ocenia możliwości poszczególnych modeli. Za całą inicjatywą stoi SpeakLesh (Spichlerz), czyli autorzy Bielika, polskiego modelu językowego.
Naturalnie większość dostępnych rozwiązań, które pojawiały się w poprzednich rankingach, radzi sobie z naszym dialektem, ale często trzeba je zmuszać do tego, aby faktycznie rozmawiały z nami po polsku. Różnie wypada jeszcze jakość poszczególnych modeli, więc wspomniany ranking także może was zainteresować.
Tymczasem dajcie znać, jak wy podchodzicie do doboru modelu LLM pod swoje potrzeby? Czy faktycznie testujecie różnie wariacje z wieloma promptami pod konkretne zadania, czy też pozostajecie przy jednym, ulubionym?
Zdjęcie otwierające: Mojahid Mottakin / Unsplash